Setting up Continuous Delivery for a Node.js REST API - Part 1
A few months back I decided to convert my hobby project - Hackathon Planner API - from pure Javascript to TypeScript. This time I sat down to build an Automated Test Suite and a Continuous Delivery pipeline around it.


Introduction
A few months back, I decided to convert my hobby project - Hackathon Planner API from pure Javascript to TypeScript and wrote a blog post aboutit. This time I sat down to build an Automated Test Suite and a Continuous Delivery (CD) pipeline around it.
Hackathon Planner API is essentially a REST API written in Node.js and Express. Stores its data in a NOSQL database (DynamoDB) and hosted on AWS Elastic Beanstalk.
I thought I would best write this up in 2 blog posts - due to the fact that most of what I did in this repository is based on some fundamental concepts which I've been reading and thinking about in the last few years.
In this post, I would like to touch on a few of these ideas that guided me in my refactoring decisions for making the codebase cleaner, less coupled and more testable.
In the next post, I'll share some more details and examples from the codebase.
Enabling Continuous Integation & Delivery
If you are not very familiar with the terms "Continuous Integration" (CI) or "Continuous Delivery" (CD) I suggest checking out ThoughtWorks website and Martin Fowler's post to learn more about these software development practices.
I've intentionally used the word "enabling" in the title above. I've seen many brownfield projects where the team wants to start practicing CI; however, depending on the age and size of the project this may turn out to be very difficult, sometimes even impossible. These are not practices that can be applied to a project only from the outside. They can't always be easily introduced as an afterthought either, they have to be built and enabled inside out; and it takes time & effort to get there!
The way I see it; practicing CI or CD are kind of a "high performance state" a team reaches after getting A LOT OF THINGS RIGHT; especially around system architecture and automated testing. Skills of the team members also matter, big time! Committing to trunk everyday without breaking stuff and more importantly, always introducing a right amount of tests at each new check-in is not an easy task for everyone.
Clean Architecture
One of the important lessons I learned from Robert C. Martin's talk Clean Architecture and Design (more resources here) is that, it's almost always a good idea to keep your business logic, the heart of your system, clean from external concerns like frameworks and delivery mechanisms (web frameworks, native application hosts, operating systems etc.).
This is beneficial in many ways. Keeps your business logic clean and free from the complexities of the environment around it. It also enables great automated testing capabilities which is probably the most important prerequisite of "Continuous Integration" way of working and delivering software.
Btw, just because I'm referring to Robert C. Martin's clean architecture here doesn't mean I agree with everything he's suggesting there - like f.ex his claim on: "storage is an insignificant detail". I'd still like to think of storage interaction as an integral part of my system. More on that in a bit.
Vertical Slices instead of Horizontal Layers
We've all built n-tier applications where software is structured in horizontal layers - most typical layers being Presentation, Business and Data Access. I've built many applications in this way and it's almost certain that I'll come across many others in the future.
What's the promise of n-tier and how did it become so widespread? I think this sentence from wikipedia sums it up:
N-tier application architecture provides a model by which developers can create flexible and reusable applications.
In recent years; gotten tired of repeating problems introduced by organically grown n-tier applications - like tight-coupling, bloated classes or services with multiple responsibilities, organically introduced premature/wrong abstractions; all leading up to code that has become unreadable and hard to reason about. You know you're in a "generic, reusable n-tier application" when you have to jump to definitions up and down OVER AND OVER AGAIN in order get a slightest clue about what a specific scenario is trying to achieve.
Luckily, there are alternative ideas in the community. One of my favorites is the direction Jimmy Bogard is taking in his talk SOLID in Slices not Layers, and his library MediatR that I've come to learn and love in the last few years.
I've built a few applications using MediatR where I implemented all scenarios (think of these as endpoints in a REST API) in vertical slices and kept the shared code between them to a minimum. I really enjoyed the outcome. Readability, cohesion and testability of these applications went really up.
Recently I listened Scott Allen on a podcast where he mentioned he's also a fan of vertical slicing and he has a blog post on a related idea.
One other lecture I recommend seeing is by Udi Dahan from NDC Oslo 2016: Business Logic, a different perspective where he talks about the fallacy of reuse.
Last but not least, I wrote a tiny MediatR style application/command facade in TypeScript. I do make use of this module in HackathonPlannerAPI and I'll write more about it in my next post.
Resist the temptation of sharing and reusing code unless you have a good justification and the right abstraction
Before you decide to share code between application scenarios, think twice, think three times. If you really have to do it, make sure you build a very clear interface around that component or module. Like Udi Dahan says in his
talk (shared above), USE this component from multiple scenarios, do not RE-USE it: If you find yourself tweaking the component for each new scenario that's using it, you probably got the boundary wrong. Find the right boundary or refactor this component back into the scenarios and stop sharing/reusing it.
In one of my favorite medium posts I've read recently, the author really nails it:
When Business throws more and more functionality (as expected), we sometimes react like this:
Instead, how should we have reacted:


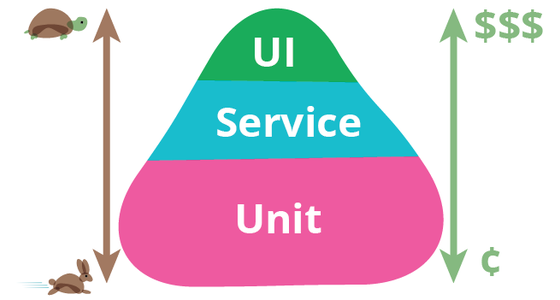
Unit or Integration... Let's call them all TESTING.
For a good chunk of my development career, I was told that the "unit" in unit test is a class. So as a result, my programming style evolved in a way that I always felt the need to design my classes with this type of testing in mind: always being able to isolate a class from its surroundings.
I understand that some call this Test-induced design damage.
Somehow in the world of C#, using Dependency Injection and programming against interfaces still feels very natural to me. So for me, this is not a big deal and I still find it useful to be able to swap things in and out as necessary and in every level of my implementation.
However, what I've come to learn eventually is this: coupling your tests to your implementation details will kill you. Just like Ian Cooper explains in his brilliant talk at NDC Oslo. So if you're writing tests for each and every single one of your classes, it's very likely that you're doing it wrong and soon you'll find out that your tests are slowing you down instead of giving you the feedback and agility you
were hoping for when you started.
Instead, find your significant boundaries. Meaningful boundaries that are composed of one or more classes and that represent business needs. The key is this: even if your implementation details change,after let's say a BIG refactoring, your tests SHOULD NOT need to change.
What is a better significant boundary than the whole application boundary? This is essentially what a MediatR style pattern gives you. One narrow facade for your whole application. What a great boundary to write your tests against!
Speed of tests matter but technology is changing too
One big reason (heck, maybe the only reason) why people will tell you to design your system in a way that you can swap out your database in favor of a test double (f.ex by using a repository pattern) is the speed of tests.
This could be a necessary evil back in the days where databases and infrastructure was bulky and slow. But is this still true? For Hackathon Planner API project I wrote 15 tests which execute all application scenarios against a DynamoDB Local Emulator, so nothing is being swapped in or out on the application side but each test sets up and tears down the NOSQL document store - so that all tests are completely isolated from each other.
The result is amazing. It takes ~2 seconds to run all the tests. Let's say if my application grows in size in the future and that I had to execute 300 tests, it would still take me below a minute to run all the tests!
I know this example will not represent every project out there in the wild for different sorts of reasons but when it does, it definitely blurs the line between "Service" and "Unit" tests in the test pyramid:
Thanks for reading. In Part 2 there will be code, I promise.
Update:
Part 2 is now available! You can find it here.
~Hakan